k8s部署pod出现evicted的解决方法
现象
在k8s中创建pod时, 突然出现如下情况
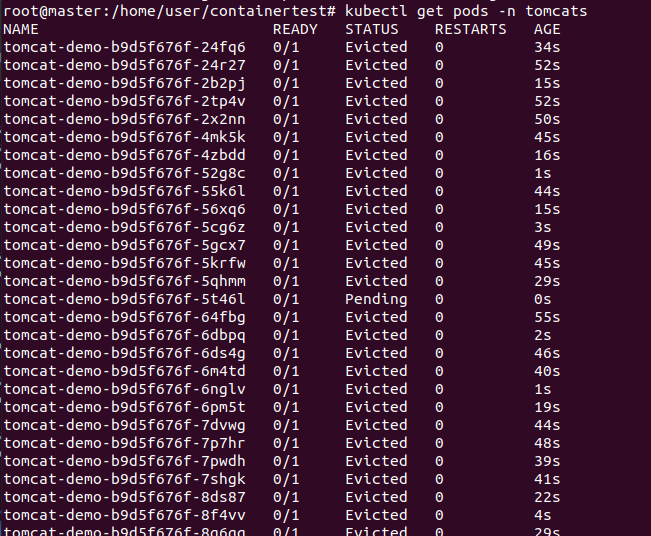
部署的yaml文件如下
1 | apiVersion: apps/v1 |
分析
经过一番调查之后, 大概理解如下
原因推测:
- 节点资源告急, 如内存和硬盘不够
- containerd配置出现问题或者冲突
治标:
- 删除被驱逐的pods: 通过
kubectl -n kube-system get pods | grep Evicted |awk '{print$1}'|xargs kubectl -n kube-system delete pods命令,删除所有的被驱逐的pod - 删除本次部署,
kubectl - 换个富裕的节点部署
治本
- 扩展节点空间, 先看看节点缺什么.
df -h和top命令分别看硬盘和内存. - 改变驱逐策略的限制, 详见下面
关于驱逐策略:
源码pkg/kubelet/apis/config/v1beta1/defaults_linux.go给出了默认的硬驱逐配置:
- memory.available < 100Mi
- nodefs.available < 10%
- nodefs.inodesFree < 5%
- imagefs.available < 15%
其中:
nodefs.available<10%:容器 volume 使用的文件系统的可用空间, 包括文件系统剩余大小和 inode 数量
imagefs.available<15%:容器镜像使用的文件系统的可用空间, 包括文件系统剩余大小和 inode 数量
- 当 imagefs 使用量达到阈值时, kubelet 会尝试删除不使用的镜像来清理磁盘空间.
- 当 nodefs 使用量达到阈值时, kubelet 就会拒绝在该节点上运行新 Pod, 并向 API Server 注册一个
DiskPressure condition.- 然后 kubelet 会尝试删除死亡的 Pod 和容器来回收磁盘空间, 如果此时 nodefs 使用量仍然没有低于阈值, kubelet 就会开始驱逐 Pod.
- kubelet 驱逐 Pod 的过程中不会参考 Pod 的 QoS, 只是根据 Pod 的 nodefs 使用量来进行排名, 并选取使用量最多的 Pod 进行驱逐. 所以即使 QoS 等级为 Guaranteed 的 Pod 在这个阶段也有可能被驱逐.
- 如果驱逐的是 Daemonset, kubelet 会阻止该 Pod 重启, 直到 nodefs 可用量超过阈值.
详见K8S官网
也就是说, 当硬盘剩余空间小于15%时, k8s会自动杀死pod, 尝试在其他节点上部署, 而我指定了noed1, 就会一直卡在创建->驱逐->创建...的循环
科学解法
最好的方法是扩容, 直接解决忧愁.
还可以通过如下改变限制策略
硬阈值设置
将以下策略加入到master和node的/etc/kubernetes/kubelet.env, 即kublet启动参数即可
1 | --eviction-hard=memory.available<256Mi,nodefs.available<1Gi,imagefs.available<1Gi \ |
第一行表示当memory<256Mi, nodefs<1G, imagesfs<1G, 时才会触发硬驱逐策略
第二行表示最小驱逐回收策略, 就是一旦驱逐策略被触发, 则要一直驱逐直到低于此行策略的阀值为止, 为了就是防止刚刚触发硬驱逐策略, 驱逐完之后没一会资源又涨上来了, 导致要反复驱逐的现象
第三行是为了防止node节点状态振荡
软阈值设置
1 | --eviction-soft=memory.available<10%,nodefs.available<15%,imagefs.available<15% \ |
第一行表示软驱逐阀值, 使用百分比代替
第二行表示触发软驱逐后, 等待执行的时间, 若此时间内低于阀值, 则不再进行驱逐
第三行为pod宽限时间
修改驱逐阈值
在/etc/kubernetes/manifests/kube-contoller-manager.yaml添加:
--terminated-pod-gc-threshold=1
此值设定了Eviction pod最大的产生个数, 默认为12500, 最小改为1, 若为0, 则表示没有限制.
最后, 重启
systemctl restart kubelet
玄学解法
但是, 实际上我做完这些操作之后都没有立刻起作用. 却通过如下解决了…
- 重启虚拟机
- 让子弹飞一会儿… 过了1天他就自动好了
或许运维就是这样的玄学吧:😂:…
参考文章:
本博客采用 CC BY-NC-SA 4.0 许可。转载请声明来自 Juice's Blog!